E-learning 2. Analýza dat 2.1. Obecný průběh analýzy 2.1.2. Porovnávání skupin (vyhledávání rozdílů mezi skupinami) 2.1.2.2. Testování hypotéz
Existuje velké množství statistických testů, ale my popíšeme pouze ty nejpoužívanější. Metody pro testování hypotéz, které nám pomáhají rozhodnout, mohou být děleny podle počtu skupin, které porovnáváme, a podle toho, zda data pochází z nějakého typu známého statistického rozdělení. Poslední podmínka dělí metody statistického testování do dvou hlavních skupin - parametrické a neparametrické metody.
Parametrické metody předpokládají, že data pochází z nějakého známého statistického rozdělení (Gaussovo, Chí-kvadrát,...). To znamená, že děláme nějaké předpoklady na parametry tohoto rozdělení (odtud název parametrické metody). Pokud data nesplňují předpoklady testu, pak výsledek, který získáme, může být velmi matoucí. Tudíž je velmi důležité zkontrolovat předpoklady rozdělení před použitím testu.
Neparametrické metody nedělají téměř žádné předpoklady na parametry a jsou na rozdělení nezávislé. Tyto metody nepočítají s numerickými hodnotami proměnných, ale jen s jejich pořadími. Tzn., že data musí být ordinální (musí být řazena).
Samozřejmě, že neparametrické metody mohou být použity na všechny typy ordinálních dat, dokonce i když data splňují podmínky některých parametrických metod. Parametrické metody mohou být použity pouze na data splňující podmínky rozdělení. Obecně se u parametrických metod předpokládá, že mají větší statistickou sílu než neparametrické metody. Statistická síla je schopnost testu tvrdit, že neexistuje žádný rozdíl, pokud tam žádný rozdíl není (nalézt skutečně negativní výsledky). To je důležité kvůli tomu, aby se nedostávalo příliš mnoho falešně pozitivních výsledků. Z tohoto důvodu se doporučuje používat spíše parametrické metody, je-li to možné. Další odlišností je, že jsou založeny na součtu pořadí v každém vzorku a testují rovnost mediánů jiným způsobem, než kterým testují parametrické testy. Jinými slovy, testují šanci získání lepších pozorování v jednom vzorku proti jiným.
Dále probereme hlavní parametrické a neparametrické testy, které mohou být použity k porovnání skupin v analýze genomických a proteomických dat. Dělí se podle počtu skupin, které porovnávají.
Volba statistického testu je založena na počtu skupin, které budeme porovnávat, a zda profily exprese genů skrze vzorky mají normální rozdělení nebo ne.
Pokud jsou genové exprese normálně rozděleny, můžeme aplikovat parametrické testy např. T-test nebo ANOVA. V případě ne-normality by měly být použity jejich neparametrické alternativy, jako jsou Mannův-Whitneyův U test nebo Kruskalův-Wallisův test. Tyto testy u dat nepředpokládají normální rozdělení. T-test a Mannův-Whitneyův U test jsou používány v porovnávání dvou skupin, zatímco ANOVA a Kruskalův-Wallisův test porovnávají více než dvě skupiny.
Porovnávání dvou skupin
Parametrické testy
Jeden z nejjednodušších parametrických testů je jednovýběrový t-test. Předpokladem je, že měření pochází z normálního rozdělení. Je vytvořen k porovnání střední hodnoty skupiny vzorků s určitou pevně danou hodnotou (s ohledem na hypotézu). Před provedením testu musíme zkontrolovat předpoklad normality. Tento předpoklad může být testován použitím např. Shapirova-Wilkova nebo Kolmogorovova-Smirnova testu.
Statistika pro jednovýběrový t-test je dána jako
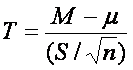
kde M je střední hodnota vzorku, µ je střední hodnota populace (podle hypotézy), S je směrodatná odchylka vzorku a n je počet pozorování.
Pokud chceme porovnat dvě skupiny, použijeme již zmíněný dvouvýběrový t-test, který je vytvořen k porovnání středních hodnot vzorku mezi dvěma skupinami. Stejně jako u jednovýběrové verze, musí být zkontrolován předpoklad normality u obou skupin. Další předpoklady jsou, že pozorování musí být nezávislá a směrodatné odchylky skupin se musí rovnat (σ1 ~ σ2). Předpoklad rovnosti směrodatných odchylek může být zkontrolován pomocí Levenova testu. Testová statistika pro dvouvýběrový t-test je dána jako
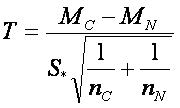 ,
,
kde 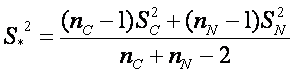 , kde MC a MN jsou střední hodnoty skupin, SC a SN jsou směrodatné odchylky skupin a nC a nN jsou počty pozorování vztahující se k rakovinné a normální skupině.
, kde MC a MN jsou střední hodnoty skupin, SC a SN jsou směrodatné odchylky skupin a nC a nN jsou počty pozorování vztahující se k rakovinné a normální skupině.
Pokud jsou pozorování mezi skupinami závislá, například pokud pochází od stejného jedince, pak by měl být použit párový t-test . Například když porovnáváme genovou expresi pacientů před a po léčbě nebo v době diagnózy a při kontrole.
Tento test je založen na vzorcích odpovídajících párů a předpokládá, že rozdíly mezi páry jsou normálně rozděleny. Párový t-test můžeme redukovat na jednovýběrový t-test testováním nulové hypotézy, že rozdíly mezi dvěma pozorováními jsou rovna nule. Testová statistika je podobná jednovýběrové variantě a je dána jako
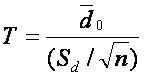 ,
,
kde d0 je střední hodnota rozdílů mezi párovými vzorky, Sd je směrodatná odchylka rozdílů a n je počet vzorků (! Všimněte si, že toto n je rovno počtu vzorků, ne počtu hodnot genové exprese, které je zdvojnásobeno, protože máme dvě hodnoty pro každý vzorek (před & po léčbě / diagnóza & kontroly)!).
Neparametrické testy
Wilcoxonův test, Mannův-Whitneyův test
Pokud data nepochází z normálního rozdělení, nemůžeme již spoléhat na parametrické metody. Zde přichází jako na zavolanou neparametrické metody, které nepředpokládají data normality. Jak již bylo zmíněno, v porovnání s parametrickými testy jsou méně silné, zavrhují oproti nim falešné hypotézy s menší pravděpodobností.
Uvedeme dva základní neparametrické testy: dvouvýběrový Mannův-Whitneyův test a jeho párovou variantu Wilcoxonův test.
Ve dvouvýběrovém Mann-Whitey testu je situace podobná jako u dvouvýběrového t-testu. Potřebujeme dvě nezávislé skupiny se srovnatelnými pozorováními a samozřejmě také musí být pozorování nezávislé v rámci každé skupiny.
Testujeme nulovou hypotézu, že dva vzorky jsou taženy ze stejné populace, a proto jejich rozdělení pravděpodobností (neznámá) jsou shodná. Alternativní hypotéza je, že existují rozdíly mezi dvěma skupinami. Výpočet testové statistiky U je jednoduchý. Nejprve ze všeho přiřadíme každému pozorování pořadí v rámci všech pozorování (dvě skupiny dohromady). Pak počítáme součet pořadí ze všech pozorování v první skupině (označíme R1), a ekvivalentně součet pořadí všech pozorování ve druhé skupině (R2). Pak jsou testové statistiky počítány pro každou skupinu a jsou dány jako
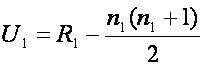 , a ekvivalentně
, a ekvivalentně 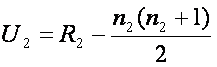
Pak porovnáváme min(U1, U2) s tabulkovými kritickými hodnotami pro daná n1, n2, a zvolenou hladinou významnosti. Pokud je min(U1, U2) menší než tabulková kritická hodnota, zamítáme nulovou hypotézu a tvrdíme, že je mezi dvěma skupinami rozdíl.
Wilcoxonův párový test je neparametrická alternativa k párovému t-testu. Je stejně jako párový t-test založen na rozdílech mezi měřeními. Označme Xi, Yi pozorování vzorku i a pak počítejme rozdíl mezi těmito pozorováními Zi=Yi-Xi pro i = 1,..., n pro každý vzorek. Uspořádáme rozdíly a testujeme nulovou hypotézu, že jsou rozdíly symetrické kolem nuly pomocí testové statistiky definované jako
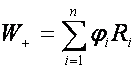 ,
,
kde Ri je pořadí subjektů i řazených |Zi| hodnot, 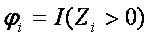 , kde I(.) je indikátor funkce a n je počet subjektů.
, kde I(.) je indikátor funkce a n je počet subjektů.
Porovnání vícenásobných skupin
Parametrické metody
Analýzy rozptylu (ANOVA)
Když máme k porovnání více než dvě skupiny, pak aplikujeme analýzu rozptylu, známou jako ANOVA. Je to skupina modelů a rozlišujeme tři typy těchto modelů:
- model s pevnými efekty, ve kterém předpokládáme, že data pochází z normálních rozdělení, která se mohou lišit pouze ve svých středních hodnotách
- model s náhodnými efekty
- model se smíšenými efekty kombinující efekty pevné a náhodné
Existují různé typy ANOVA závisející na počtu úprav a způsobu, jakým jsou aplikovány na subjekty v experimentu. Rozlišujeme několik typů ANOVA: One-way ANOVA (jednofaktorová ANOVA), Two-way ANOVA (dvou-faktorová ANOVA) nebo factorial ANOVA.
Teorie modelů ANOVA je podrobněji vysvětlena zde:
Následující tabulka může sloužit jako průvodce při výběru metody k testování hypotéz podle typu dat a porovnávání:
.jpg)