E-learning 2. Analýza dat 2.1. Obecný průběh analýzy 2.1.2. Porovnávání skupin (vyhledávání rozdílů mezi skupinami) 2.1.2.2. Testování hypotéz
Testování hypotéz je nepochybně jednou z nejoblíbenějších částí statistiky rozšířené v mnoha vědních oborech. Jde o standardizovanou a dobře interpretovatelnou metodiku, která hraje v analýze genomických a proteomických dat důležitou roli. Zejména když hledáte odlišně exprimované geny/proteiny mezi skupinami. Máte-li nějaké předpoklady a chcete testovat, zda je to pravda, vyžadujete ve skutečnosti dvě výlučná tvrzení, která jsou ve statistice nazývaná hypotézy. Tvrzení, které říká: “Mezi testovanými skupinami není žádný rozdíl” se nazývá nulová hypotéza a tvrzení říkající: “Mezi testovanými skupinami je rozdíl” se nazývá alternativní hypotéza.
Výsledek statistického testu se nazývá významný, pokud je nepravděpodobné, že jev nastal náhodně. Síla důkazu této "nepravděpodobnosti" je známa jako hladina významnosti nebo p-hodnota. Nyní musíme zdůraznit, že existují dva různé přístupy testování hypotéz, často v mnoha statistických učebnicích zaměňovány.
Obvyklé Fisherovo testování hypotéz, také spíše zvané testování významnosti, nezvažuje existenci alternativních hypotéz a výsledkem testování je buď zamítnutí, nebo potvrzení nulové hypotézy. To znamená, že zamítnutím nulové hypotézy nepřijímáme alternativní hypotézu. P-hodnota je v tomto kontextu definována jako pravděpodobnost, že pokud nulová hypotéza platí, získáme pozorovaná nebo více extrémní data. Pokud je p-hodnota dost malá (pravděpodobnost získání takové hodnoty, pokud není rozdíl v expresi genů, je malá), můžeme říci, že nulová hypotéza je nepravdivá, nebo že vznikl vzácný případ.
Alternativní přístup uvedli později Neymann & Pearson. Tento přístup vyžaduje definici alternativní hypotézy. Přístup pracuje s pravděpodobností zamítnutí nulové hypotézy, pokud je pravdivá (falešně pozitivní výsledky). Použitím statistického testu v tomto přístupu musíte učinit rozhodnutí, která z hypotéz je právě pravdivá. Nicméně, když děláme takové rozhodnutí my (nebo spíše statistický test), může být buď správné nebo ne. Existují dvě možné chyby, které mohou nastat:
Chyba I. druhu znamená, že zamítáme nulovou hypotézu, i když ve skutečnosti platí. Přesněji tvrdíme, že je mezi testovanými skupinami rozdíl, i když mezi nimi ve skutečnosti žádný rozdíl není. Tato chyba se také nazývá α chyba nebo falešně pozitivní výsledek (pojem pozitivní výsledek znamená ve statistice zamítnutí nulové hypotézy).
Chyba II. druhu znamená, že nezamítneme nulovou hypotézu, i když neplatí: tvrdíme, že mezi testovanými skupinami není žádný rozdíl, i když ve skutečnosti mezi nimi rozdíl je. Tato chyba se také nazývá β chyba nebo falešně negativní výsledek.
Všechna čtyři možná rozhodnutí jsou shrnuta v následující tabulce.
| ROZHODNUTÍ | ||
| SKUTEČNOST | Nezamítáme H0 (Tvrdíme, že zde není žádný rozdíl) |
Zamítáme H0 (Tvrdíme, že skupiny jsou odlišné) |
| H0 platí (Mezi skupinami není žádný rozdíl) |
Správné rozhodnutí |
Chyba I. druhu (α chyba) |
| H0 neplatí (Skupiny jsou odlišné) |
Chyba II. druhu |
Správné rozhodnutí |
Rozhodovací pravidla musí být navržena tak, aby se minimalizovaly obě chyby.
P-hodnota a α chyba jsou často nejasné pojmy. Všimněte si, že α chyba je pravděpodobnost zamítnutí nulové hypotézy, i když skutečně platí, když je test mnohokrát opakován! P-hodnota je samotná pravděpodobnost získání pozorovaného nebo více extrémního výsledku, pokud nulová hypotéza platí. NENÍ to pravděpodobnost, že je nulová hypotéza pravdivá (např. NENÍ to pravděpodobnost, že mezi skupinami není žádný rozdíl).
Prosím, přečtěte si následující článek vysvětlující rozdíl mezi p-hodnotou a α chybou: http://ftp.isds.duke.edu/WorkingPapers/03-26.pdf
P-hodnota je získána jako výsledek každého statistického testu. Nicméně, je na analytikovi, aby rozhodl, která p-hodnota je považována za významnou, to znamená stanovit rozdíl mezi skupinami (zamítnutí nulové hypotézy). Hranice pro p-hodnotu musí být nastavena před testováním hypotézy. Nejčastější nastavení je na hodnotu 0,05 (hladiny významnosti), což znamená, že je pouze 5% šance získání takového výsledku, pokud mezi skupinami není žádný rozdíl. Jinými slovy, když testujeme 1000 genů, pak 5% z nich (50) bude mít p-hodnotu rovnu nebo menší než 0,05 pouze náhodou, bez odlišné exprese mezi skupinami. Tudíž můžeme očekávat 5% náhodných falešně pozitivních výsledků.
Princip testování hypotéz
Jak takový statistický test pracuje a co porovnává? Víme, že srovnává dvě nebo více skupin, ale jak? K zodpovězení této otázky si musíme nejprve uvědomit, co se pokoušíme porovnávat. Jestliže měříme genovou expresi genu ve dvou skupinách, pak máme zajisté k dispozici hodnotu genové exprese pro všechny vzorky v každé skupině. Představme si, že porovnáváme expresi genu mezi dvěma skupinami, jedna je reprezentovaná normální prsní tkání, druhá nádorovou prsní tkání. Naše datová sada s mírami genové exprese jednoho genu může vypadat takto:
| Skupina | Gen A |
| Normal | 2,3 |
| Normal | 3,0 |
| Normal | 0,5 |
| Normal | 1,9 |
| Normal | 1,8 |
| Normal | 2,4 |
| Normal | 0,9 |
| Normal | 3,1 |
| Normal | 1,7 |
| Normal | 1,3 |
| Cancer | 6,1 |
| Cancer | 7,2 |
| Cancer | 4,6 |
| Cancer | 3,8 |
| Cancer | 5,2 |
| Cancer | 5,5 |
| Cancer | 6,4 |
| Cancer | 9,2 |
| Cancer | 8,4 |
| Cancer | 4,6 |
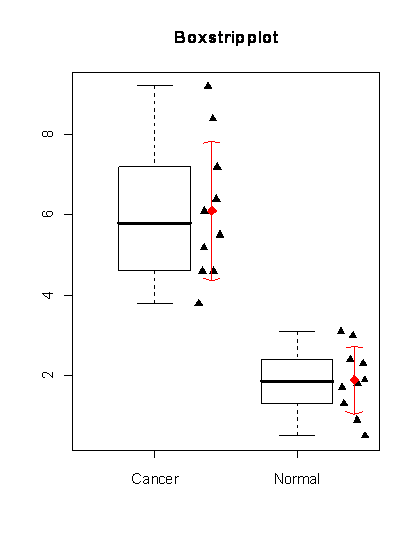
První sloupec je skupina proměnných, druhý sloupec obsahuje míry exprese pro gen A. Obrázek na pravé straně je grafická reprezentace dat. Krabicové grafy představují medián, 25-75% kvantily a odlehlou oblast, červené body představují konkrétní střední hodnoty a šipky směrodatné odchylky. Trojúhelníky reprezentují hodnoty genové exprese vzorků.
Jeden z nejjednodušších způsobů jak zjistit, zda jsou skupiny odlišné, je podívat se na graf. Při pohledu na graf intuitivně porovnáváme body a nevidíme žádný překryv mezi skupinami. Navíc střední hodnota skupiny s rakovinou je > 6, zatímco střední hodnota normální skupiny je < 2. Statistické testy dělají něco podobného, ale používají míry zvané statistiky. Krásným příkladem statistiky je T-statistika z dobře známého dvouvýběrového T-testu. Tato míra porovnává střední hodnoty a rozptyl dat mezi skupinami. Rozptyl je porovnáván přes směrodatné odchylky. Statistika je počítána následovně:
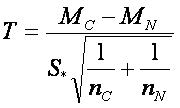 ,
,
kde 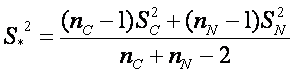 , kde MC a MN jsou střední hodnoty skupin, SC a SN jsou směrodatné odchylky skupin a nC a nN jsou počty pozorování týkající se rakovinné a normální skupiny.
, kde MC a MN jsou střední hodnoty skupin, SC a SN jsou směrodatné odchylky skupin a nC a nN jsou počty pozorování týkající se rakovinné a normální skupiny.
Pokud v genové expresi mezi skupinami není žádný rozdíl, pak by rozdíl mezi středními hodnotami skupin měl být blízký 0. V tomto případě má statistika T normální rozdělení se střední hodnotou 0:
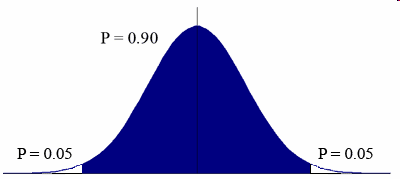
T-test pro náš gen počítá hodnotu T-statistiky, a pak porovnává jeho hodnotu s tímto rozdělením podle nulové hypotézy. Pokud je T-statistika extrémní ve srovnání s rozdělením T-statistiky, pak můžeme říct, že existuje rozdíl v genové expresi mezi rakovinnou a normální skupinou. “Extrémnost” T-statistiky je vlastně její p-hodnota.
V následující části popíšeme několik základních metod, které nám pomohou udělat statisticky správné rozhodnutí mezi nulovou a alternativní hypotézou.