E-learning 2. Analýza dat 2.2. Analýza vysokopokryvných genomických dat 2.2.1. DNA mikročipy 2.2.1.11. Analýza biologických drah
2.2.1.11.1.Úvod
Ačkoli každý mikročipový experiment začíná biologickou otázkou, všechny první kroky po hybridizaci se zabývají analýzou dat, a proto jsou silně statistické a matematické povahy. Předzpracování čipu může v závislosti na tom, jaká technologie je použita, zahrnovat různé nestandardní statistické nástroje jako neparametrické vynesení křivky (non-parametric curve fitting), transformace stabilizující rozptyl a množství robustních statistických metod. Následná detekce odlišně exprimovaných genů značně spočívá v testování statistické hypotézy a opět používá pokročilé techniky jako empirické Bayesovské metody nebo komplexní vzorkovací strategie. Přestože je mnoho těchto nástrojů implementováno uživatelsky přívětivým softwarem, jsou typicky ovládány statistikem nebo bioinformatikem, kteří vědí, jak tyto metody nejlépe použít. Biologický vědec rád vidí, jako první výsledky svého experimentu, přiklání se k „čestnému místu“ pořadí odlišně exprimovaných genů s ohledem na p-hodnoty nebo nějaké jiné skóre.
Pro názornou ukázku použijeme veřejně dostupnou sadu dat, která byla publikována Lee et al. [2005]. Tito autoři porovnávali tukovou tkáň mezi obézními a hubenými Pima Indiány, skupinou Amerických Indiánů, která je specificky náchylná k obezitě. Vzorky byly hybridizovány na HGu95e-Affymetrix čipech (12639 genů/sondových sad) a experiment je dostupný jako GDS1498 v GEO databázi (http://www.ncbi.nlm.nih.gov/sites/GDSbrowser?acc= GDS1498). Vybrali jsem pouze mužské vzorky kvůli zredukování komplexnosti datové sady, tj. máme 10 obézních subjektů, které porovnáváme proti 9 hubeným subjektům. Použitím Bioconductor knihovny limma jsme provedli střední t-test k porovnání dvou skupin. V tabulce 2.2.1.11.1 vidíme seznam všech genů, které mají Benjamini-Hochberg-nastavení p-hodnoty nižší než 5%. Toto by byl typický výsledek, který biolog získá ze souboru jako „výsledek“ svého experimentu.
Tabulka 2.2.1.11.1. Seznam všech genů s nastavenými p-hodnotami nižšími než 5%
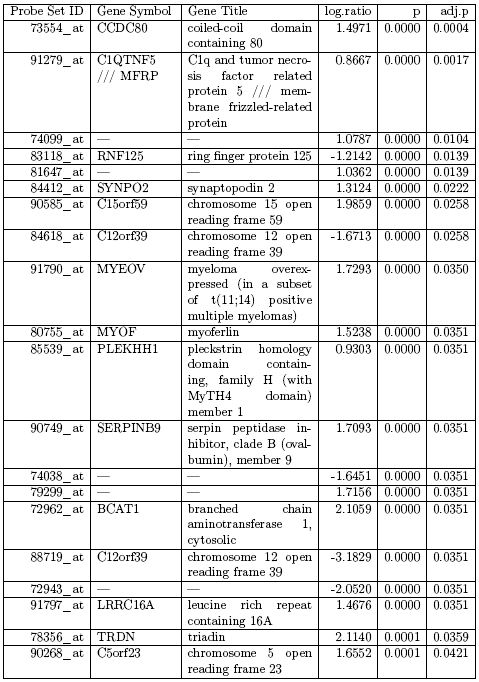
Tato tabulka obsahuje celkově 18 genů. Některé z nich biolog může znát, pro jiné může použít internetové zdroje, jako jsou genové databáze nebo dokonce Wikipedii, aby o nich více zjistil. Například může z literatury vědět, že gen RNF125 souvisí s imunitní odpovědí. Ale znamená to automaticky, že imunitní odpověď u obézních subjektů je jiná než u hubených subjektů?
Toto je druh otázky, kterou se analýza biologických drah a genových sad pokouší zodpovědět. Všechny geny na našem čipu, které souvisí s imunitní odpovědí, tvoří to, čemu říkáme genová sada. A spíše než přiřazení skóre (např. p-hodnoty) samostatným genů jako v tabulce 1, chceme skóre přiřadit kompletní genové sadě. V tomto článku je přehled některých principů tohoto druhu analýzy. Není naším záměrem uvést vyčerpávající přehled všech metod; pro tento typ přehledu jsou dobré články od Nam and Kim [2008] a Huang et al. [2009]. Tento text je spíše pojat jako úvod do problematiky pro čtenáře, kteří jsou v této oblasti nováčci.
V 2. části popíšeme, jak lze identifikovat geny na našem mikročipu, který náleží genové sadě například takové, která je spojena s imunitní odpovědí. Uvedeme některé základní internetové databáze, které takové informace poskytují, a obzvlášť projednáme různé typy genových sad, které mohou být použity. V 3. části prostudujeme některé principy, které testují, zda je daná genová sada významně odlišně exprimována. Nebudeme moc detailně probírat velké množství různých metod, které jsou k tomuto účelu navrženy, ale raději vysvětlíme některé nejdůležitější části, ze kterých se tyto metody skládají, a různé základní principy v jejich pozadí. Zvláště se zaměříme na rozdíl mezi uzavřenými (self-contained) a kompetitivními (competitive) metodami. V 4. části se podíváme na některé vybrané softwarové nástroje, které vykonávají analýzu genových sad a článek zakončíme některými závěry v 5. části.